Usuniemy wszystkie wystąpienia dużych i małych liter polskiego alfabetu. Zastosujemy odpowiedni zakres znaków typu Unicode.
Dane źródłowe
W tabeli danych mamy imiona i nazwiska osób. Przy tych danych są niepotrzebne znaki liczbowe, które należy usunąć.
Dane prezentują się następująco:

Usuwanie polskich znaków
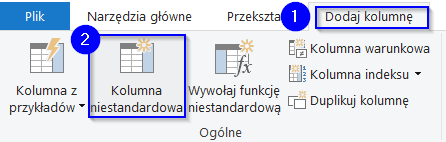
- Dodaj kolumnę niestandardową
- Przejdź do zakładki „Dodaj kolumnę”
- Wybierz opcję „Kolumna niestandardowa”
- W pasku formuły wpisz funkcję:
Text.Remove([dane], {"a".."z","A".."Z","Ą","ą","Ć","ć","Ę","ę","Ł","ł","Ń","ń","Ó","ó","Ś","ś","Ź","ź","Ż","ż"})Funkcja usuwa w kolumnie [data] wystąpienia wszystkich małych liter w podstawowym alfabecie {„a”..”z”}, a następnie wielkie litery {„A”..”Z”}. Po przecinku wypisane są polskie znaki diakrytyczne: ą, ę, ć itd. Ważne, aby wypisać te znaki w dużym i małym formacie. W jednej parze cudzysłowów może być tylko jeden znak.
Po zatwierdzeniu funkcji edytor Power Query powinien prezentować się następująco:

Uwaga!
Dlaczego nie można wpisać {„A”..”z”}?. Teoretycznie jest to poprawny zapis. Należy pamiętać, że nie wybieramy zakresu znaków według alfabetu standaryzowanego tylko wg „alfabetu” listy znaków Unicode. Alfabet Unicode dzieli się na grupy i jest sortowany według własnych zasad.
{„A”..”Z”} to grupa Latin Alphabet Uppercase
{„a”..”z”} to grupa Latin Alphabet Lowercase
Pomiędzy grupą Uppercase i Lowercase znajduje się grupa ASCII Punctation & Symbols, która zawiera takie znaki: [ \ ] ^ _ `
Dlatego jeżeli wpiszemy zakres {„A”..”z”} to dodatkowo zostaną usunięte powyższe znaki.